A PLAY-BY-PLAY GUIDE FOR CONSTRUCTING AN AGILE DATA ECOSYSTEM THAT ACCELERATES DATA-DRIVEN VALUE
Table of Contents
- Why You Need a Data Strategy 2
- Explore the 5 Essential Components of Every Successful Data Strategy 3
- Your Data Strategy is Complete: The End of the Beginning 4
- Case Study: Impact Makers Built a Data Strategy for a $10B Financial Services Company to Drive Investment in Analytics Capabilities 5
- How To Build a Modern Data Ecosystem 6
- Modern Data Ecosystem Best Practices 7
- Public Cloud is the Ideal Location for Most Modern Data Ecosystems 8
- Improve the Reliability of Data Transfers With Data Exchange Mediators 9
- Bake-In Data Privacy and Governance 10
- Optimize Information Delivery, Interaction & Insight While Reducing Risks 11
- Getting the Data Stores Right is Paramount to Success 12
- Data Lakes vs Data Warehouses; Which is Better? 13
- Agile Data Warehousing Provides Speed to Insights 14
- Data Vault Supports Agile Data Warehousing 15
- It’s Time to Set Sail on Your Modern Data Ecosystem 16
Let’s face it; the business world is drowning in data. As a data leader, the immeasurable value that remains untapped from your organization’s sea of data is likely an exciting and equally overwhelming subject to contemplate. With most enterprise organizations clocking in at over 200 cloud-based applications supporting their operations and collecting data, managing the flow of that data and producing meaningful insights amounts to a titanic responsibility.
To exacerbate the problem, your apps are capturing more finely grained data, more frequently and third-party sources of data promise to give you a competitive edge or keep you from sinking. In addition, your analysts and data scientists want a deeper history in order to spot trends and predict future outcomes, and you know there are key insights better data management can help uncover.
The possibilities for extracting, storing, securing, and processing data are endless thanks to modern technology and innovative methods. Public and specialty clouds, platforms-as-a-service (PaaS), and out-of-the box AI algorithms have all flooded the marketplace. Everything has a unique application, and everything has a separate price tag.
You know that the right decisions can make waves but with so many places to start, how can you feel confident that your choices will accelerate data-driven value in your organization? How can you chart a course for the future, while also preventing costs from going off the deep end, as new data opportunities surface?
WHY YOU NEED A DATA STRATEGY
Your organization doesn’t go to market without guidance from a strategic plan, and a strategic plan doesn’t get assembled without consideration of your company’s mission and goals.
If you want your organization to sail in the right direction and not get waterlogged with technology for technology’s sake, you need a data strategy that serves as your ‘North Star.’
Get started by grounding yourself in your company’s mission, objectives and desired key results and translate them into a data strategy. Ask yourself, “where is the data-driven value?” The needs of your business will drive the requirements of your data strategy, and the value-based outcomes you define will serve as a guide to measure return on investment.
To formulate an effective data strategy, your framework should give consideration to five key areas: data governance, architecture, analytics and data science, technology, and organizational adoption. Failure to plan in any of these areas will lead to challenges downstream and could result in a failure to launch or early obsolescence of your strategy.
EXPLORE THE 5 ESSENTIAL COMPONENTS OF EVERY SUCCESSFUL DATA STRATEGY
1. DATA GOVERNANCE
Data governance will help identify and prioritize business initiatives for shaping data standards and solutions to create value-added outcomes. Your data governance standards and policies will define conventions for availability, usability, integrity and security of the data in your ecosystem. Failure to include data governance in your planning could lead to inconsistent data, poor data quality and the misuse of data within your organization.
2. ARCHITECTURE
Architecture provides a blueprint for organizing and connecting data assets for optimal use, including interoperability, security, access, and efficiency. Taking the time to map out the architecture will help you identify and fill gaps in your strategy, and it will serve as a guide for maintenance and future ecosystem expansion.
3. ANALYTICS & DATA SCIENCE
Analytics and data science delivers intelligence to the organization to create value through improved decision making and process automation. Developing an analytics framework starts by asking key business questions and working backward to understand what data collection and processing methods must be used to make your data usable and allow your people to obtain valuable insights.
4. TECHNOLOGY
Technology provides the infrastructure and modern data capabilities, enabling the realization of the analytical and automation solutions. Your strategy should include details about every environment, application and algorithm deployed in the ecosystem, and the technology choices you make should be shaped around governance policies, architectural requirements, and data science conventions.
5. ORGANIZATIONAL ADOPTION
Modern data ecosystems provide little value unless the people in the enterprise utilize the data and insights afforded by the ecosystem. Your successful adoption must include change management initiatives spanning data literacy, organizational development, and process engineering to optimize data consumption and ensure value realization.
A sound data strategy will set you up for success as you build your modern data ecosystem; it will also fill your sails well into the future. As a result of completing this step as thoroughly as possible, you can expect to extract idle business value from the data you already have, create new business value by interpreting data in new ways, and potentially monetize your data by making it available to others. You should plan to see these benefits early and you can expect to constantly realize new opportunities to produce business value with ease as you look to leverage your data ecosystem and execute on new analytics initiatives.
YOUR DATA STRATEGY IS COMPLETE: THE END OF THE BEGINNING
Once you have your Data Strategy, what’s next? Maybe you’ve picked a data science toolkit (or two or three) and you’re feeling accomplished. Or perhaps you’ve adopted the latest data warehouse platform that you were told has everything you need, but you know you’ve only reached the end of the beginning.
Executing a data strategy requires more than a single system or platform. It takes a system of systems plus the people and processes to keep data flowing smoothly. You’ll need to construct your own Modern Data Ecosystem and the data strategy you develop will serve as the blueprint for construction.
CASE STUDY: IMPACT MAKERS BUILT A DATA STRATEGY FOR A $10B FINANCIAL SERVICES COMPANY TO DRIVE INVESTMENT IN ANALYTICS CAPABILITIES
THE CHALLENGE
Our client, a $10B financial services company, sought assistance to develop a plan to mature its data capabilities as it grew other areas of the business.
It was well known throughout the organization that data capabilities were lagging; the company faced siloed data trapped in vendor packages, manual data processes to answer regulators and internal needs, data duplication, overtaxed data heroes throughout the business, and poorly understood information across the organization.
Insights were lacking, and inefficiency and risk were high.
THE !M SOLUTION
Impact Makers evaluated organizational pain points through stakeholder interviews, collecting and outlining the impact of data maturity improvements for various use cases. !m mapped current-state data capabilities to a maturity model in the areas of Governance, Architecture, Technology, and Organization, resulting in a data strategy for improving data capabilities while simultaneously delivering business value from data projects.
Hard and soft benefit calculations were generated from use cases collected during data strategy development.
A technology assessment was conducted that resulted in software recommendations for a data ecosystem.
!m developed a roadmap and outlined actionable projects to begin enhancement of data capabilities.
SERVICES DELIVERED
- Data Strategy
- Data Maturity Assessment
- Data Capability Road Map
- Business Case Development
- Analytics Program Budget Development
- Analytics Organization Design
IMPACT & RESULTS
The data strategy was used to procure funding for a new data warehouse and business intelligence system. Estimated three-year budgets were created, including the hardware, software and resource plan. Funding was dedicated to the initial investment and an ongoing program.
Collected use cases were turned into a backlog of potential data projects to begin data capability development. Those use cases are now being actively developed alongside larger data capabilities such as data governance.
HOW TO BUILD A MODERN DATA ECOSYSTEM
Your company wants to be data-driven, but how do you accomplish that goal? You need technical solutions that help you get the data, store the data, process the data and use the data. Your solutions for these capabilities need to work together, be secure against attack and data loss, be scalable (data volumes growing, users growing) and be supportable. You need a modern data ecosystem.
Modern Data Ecosystem is another name for the system of systems of a data strategy. It’s an integrated set of platforms, systems, and services used to acquire, manage, and gain value from data. It’s important to begin by creating an architecture that defines the destination (target state). Taking the time to visually map out your own data ecosystem will accelerate the build phase and support data operations into the future.
Your data ecosystem architecture will provide guardrails and guidelines that help keep your project work aligned to the long-term destination. An example architecture for a Modern Data Ecosystem is portrayed in Figure 1. Note that the diagram is flipped from typical architecture views. Because the insights you need and the information delivery you desire is the sole reason for building a data ecosystem, we recommend starting with the end in mind.
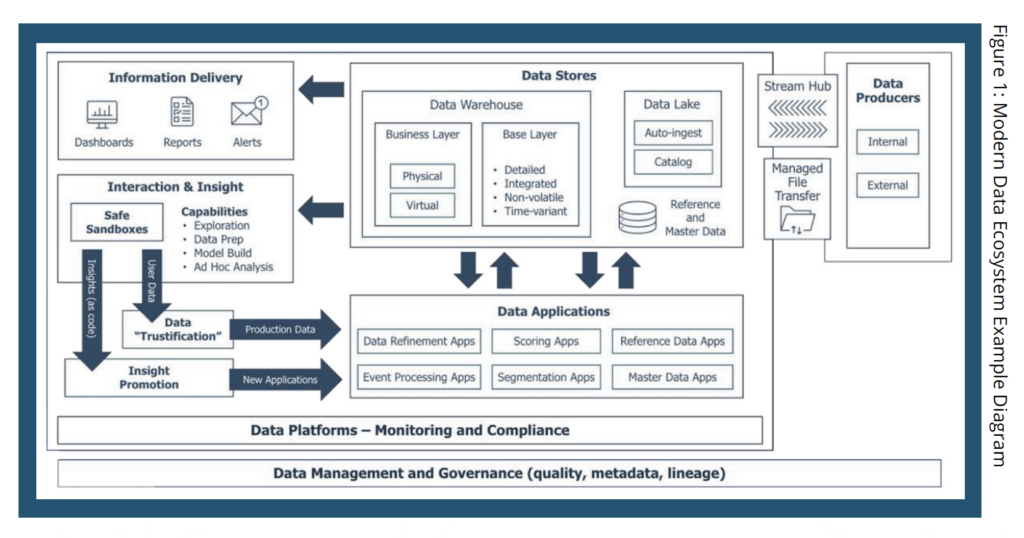
Starting from the right and moving to the left, let’s explore the technologies deployed in this example architecture to Get the Data, Store the Data, Process the Data and Use the Data.
| Watch !m data architecture leader, John Pimblett, present this example. (10-Minute Segment) |
GET THE DATA
Examples Technologies
- Stream Hub: Kafka, Amazon Kinesis
- Managed File Transfer (Bulk Exchange Hub): SFTP, S3 API, Dropbox, IBM MFT, Progress MOVEit
Your enterprise likely has data producers that exist both inside the walls of your company as well as externally. Getting data may, more traditionally, provide the data into your ecosystem through file transfer. Newer ways of getting data include streaming data to get it into your data ecosystem and gain value from it more quickly. The production of data or the importing or ingesting of data can happen once, or it may be an ongoing process.
STORE THE DATA
Example Technologies
- Data warehouse: Amazon Redshift, Snowflake, Oracle, SQL Server, Azure Synapse
- Data lake: Cloudera Data Platform, Azure Data Lake, Databricks Delta Lake, homegrown using cloud storage, many third-party add-ons (Qubole, Zaloni)
As you consider data storage solutions, how you manage, protect, and optimize the data in your ecosystem will be key to your decision. Your strategy should prioritize storing the data in ways that will be more useful and easier to understand. Two main concepts of this example architecture include the data lake and the data warehouse.
There are many ways to store data in the architecture, and how you do this will be informed by your data strategy. Some examples not shown in this diagram include low latency data stores like NoSQL, memory-based, and cache-based stores. Others include specialized database technology, like a graph database, and zones within the data lake (raw, standardized, refined, etc.).
PROCESS THE DATA
Example Technologies
- Spark, NiFi, Amazon SageMaker, Amazon Lambda/Batch/SQS/SNS, Informatica, Talend
- Many specialized fit-for-purpose engines.
- MDM/RDM: Oracle, Informatica, IBM, & many others
There is a vast range of technologies supporting the processing of data. Previously known as ETL, applications in this part of your architecture may be deployed for making the data more fit for use by refining it or changing its structure. Cutting-edge event processing applications can be triggered when events show up in the stream hub, are able to complete an action, and may put that data back onto the stream hub when the task is complete.
Other processing applications may include higher value scoring and segmentation applications coming out of your data science and machine learning work, those for basic blocking and tackling tasks included in managing your reference data, and applications for mastering your data for use in the data ecosystem as well as outside the data ecosystem.
USE THE DATA
Example Technologies
- Info Delivery: Tableau, ThoughtSpot, BusinessObjects, Power BI, hundreds more
- Interaction and Insight: R, python, SQL, Amazon SageMaker, TensorFlow, Jupyter, SAS, IBM SPSS
Use of the data is the end state you must have in mind when you plan and assemble your data ecosystem. What functions will the data serve within the organization? What refinements can be made to speed up insight attainment or maximize the value of the information to the business? How will the data be accessed? Who will have access to the data? What context will data be viewed through to apply insights to practice?
Well-managed self-service capabilities that are designed to mitigate risk are key to the function of your data ecosystem. Any enterprise is vulnerable to data loss or exposure of personally identifiable customer or employee information. The need to make data available to your team, and potentially to third parties, is somewhat in conflict with the need to secure data, so these needs must be balanced carefully.
Understanding how to make the data useful demands the involvement of stakeholders within your organization. Start by identifying who these stakeholders are and probe them to mount your own insight into how best to ensure data is useful across the organization.
MODERN DATA ECOSYSTEM BEST PRACTICES
PUBLIC CLOUD IS THE IDEAL LOCATION FOR MOST MODERN DATA ECOSYSTEMS
For most data ecosystems, the public cloud is the ideal location as it allows for wide access, scalability, and extendibility. Various Platform as a Service (PaaS) products including DWaaS offer further benefits. The scalable nature of these solutions allows you to pay only for the compute power you use and provide for nearly limitless, low-cost storage.
Separated storage and compute solutions offer further reduced costs and ability to “burst” your compute power when you need it, meaning you don’t have to plan for capacity ahead of time. You also don’t have to struggle with complicated resource management for shared compute.
Also available in public cloud solutions are managed services that reduce administrative overhead, sometimes to zero. In some cases, certain managed services are a standard feature.
IMPROVE THE RELIABILITY OF DATA TRANSFERS WITH DATA EXCHANGE MEDIATORS
Data exchange mediators for streams and files provide reliable data transfers. They also reduce tight coupling of sources and targets and improve manageability. Data exchange mediators can be engineered for high availability and can be scaled for throughput and performance. In addition, data exchange mediators provide support for data streaming technologies which speeds up access to data and enables new value opportunities.
A central platform for data exchange mediation makes the production support team more effective by standardizing logging and monitoring. Also available to a data exchange mediator are off-the-shelf solutions, including pre-built connectors for commonly used data sources and targets.
BAKE-IN DATA PRIVACY AND GOVERNANCE
Data privacy regulations require solutions across the entire ecosystem and include but are not limited to classification, IAM (identity and access management), encryption, and tokenization.
You can enable data democratization through data governance – specifically business glossaries and data context.
Your established policies should give consideration to where sensitive data is stored throughout the ecosystem, who has access to it, how it is protected and whether you need to strip sensitive data from tables or hide it when it’s ingested. It’s more challenging to retrofit a data ecosystem for privacy controls than it is to bake them in. If you know you’re in-scope for regulations, or expect to be, then build privacy into the ecosystem from the start.
Governance will look different for each organization but the key to success is not boiling the ocean – focus on minimal viable products and do not go overboard with the organization design. Another critical aspect of success is injecting governance processes into the software development lifecycle (SDLC); for example, loading data into a business catalog. Injecting governance processes into the SDLC ensures that critical activities are not an afterthought and potentially left out.
| Watch the presentation for more on data privacy and governance. (3-Minute Segment) |
OPTIMIZE INFORMATION DELIVERY, INTERACTION & INSIGHT WHILE REDUCING RISKS
Toolsets are not just about traditional reporting or business intelligence anymore. Today’s toolsets have advanced beyond simple reporting. Business users looking for self-service and fast insights will benefit from visualized data augmenting paginated reports.
However, self-service injects potentially many more users into your data consumption process, increasing risk of data loss or exposure. For this reason, IT teams must do additional thinking at the outset to strike a balance between information sharing while also protecting key risks and sensitive data. Be sure to plan for that and include it in your SDLC.
For data scientists, flexible analytical workbenches have a different feel than more traditional business intelligence and data warehousing tools. These provide data science users the independence to leverage open source tools and many different libraries. With elastic storage and compute, data scientists have the flexibility to operate without intervention from IT.
GETTING THE DATA STORES RIGHT IS PARAMOUNT TO SUCCESS
Of all the pieces of the modern data ecosystem, the data stores are the most important—because “it’s all about the data.” Your data movement jobs could be point-to-point and hard to support, or your reporting tool could be stuck in the 20th century and lack fancy visualizations; your data science workbench might include a dozen tools that don’t interoperate, but if your data is well-managed and stored in ways that make it understandable and useful, you’ll likely be successful. On the other hand, if you don’t get the data stores right, no amount of world-class tools will make up for that.
DATA LAKES VS DATA WAREHOUSES; WHICH IS BETTER?
Data lakes are not going away, but for most enterprises a data warehouse is a better core for the data ecosystem. Data lakes and data warehouses naturally support different grains of work.
DATA LAKE SUPPORTS:
|
DATA WAREHOUSE SUPPORTS:
|
Designing, building, and running an “enhanced data lake” (by bolting on data warehouse features) will require more resources than you bargained for. Beware the slippery slope of the sunk cost fallacy! In addition, file-based storage does not support record- and key-level operations and leads to frustration in use cases which require it. You can have an agile infrastructure, but if your data architecture and delivery processes are stuck in the past, your data won’t be agile.
Whereas a data lake typically has data stored in many types of files, with different layouts and data types, a data warehouse has standardized storage, a data dictionary and data types. In the end, a data warehouse and a data lake are just vehicles. For these reasons, a data warehouse provides a better foundation than a data lake.
If you’ve been a party to data warehousing initiatives in the past, you may be thinking that it’s data warehouses that have become obsolete. But they have evolved and several alternatives to Kimball-only data warehouses exist, enabling more incremental and faster delivery of business value. The goal should always be an increase in value or a reduction in risk for the enterprise, not the buildout of some technical solution. Remember, value is never realized by managing data but rather by using it.
| Understand the challenges of a traditional data warehouse. (2-Minute Segment) |
AGILE DATA WAREHOUSING PROVIDES SPEED TO INSIGHTS
If you are just starting out it may seem overwhelming. There are countless data sources and even more business opportunities. But your Data Strategy should have helped uncover your value propositions and use cases. Building iteratively with the business value in mind will reduce up-front and downstream costs and it will enable growth and flexibility as business needs change.
Examples of business value that could be extracted from your data ecosystem include increasing revenue, improving customer satisfaction and outcomes, improving efficiency, mitigating and avoiding risk, and meeting regulatory compliance. Using the strategy outlined herein, you’ll chart a course that allows the delivery of insights early, while providing incremental opportunities for value creation as time passes.
Remember, your business informs the data strategy, your data strategy guides the value proposition and defines the use cases, and your use cases determine the data to source and build. Your use cases will also define downstream efforts to source, load and design data. As you plan, be on the lookout for data clusters will satisfy many business use cases. Before you get to work, prioritize your build and delivery efforts and build a production backlog. This will provide you with a clear starting point and you’ll always know which step to take next in order to deliver greater business value.
DATA VAULT SUPPORTS AGILE DATA WAREHOUSING
Traditional data warehousing made it difficult to handle agile delivery and a “build it piece-by-piece, and change often” approach.
Unlike traditional data warehousing, Data Vault includes an architecture, a modeling approach, and a methodology. This includes a layered architecture that reduces complexity for users and enables engineering optimization. Separate layers can be on different technologies and tuned for cost and performance.
It also supports independent, parallel loading of full-fidelity data to the data warehouse with precise auditability. Once full-fidelity, auditable data is in Data Vault, you might choose to delete the source files or objects. This will help reduce risks as well as costs associated with keeping all of your files (you don’t have to scrub for GDPR or CCPA if the files don’t exist).
Data Vault relies on a handful of design patterns using hubs, links and satellites – all oriented around Business Keys. These natural identifiers typically used in business processes (such as an Employee ID) are often more stable and long-lived than source systems.
In addition, Data Vault designs are naturally extendible for new and changed sources, often with no refactoring of the existing model or loading code. The business layer, typically dimensional designs, can be provisioned virtually or physically using Data Vault. Predictable design patterns encourage automation and code generation.
| View example technologies across a Data Vault-based ecosystem. (2-Minute Segment) |
IT’S TIME TO SET SAIL ON YOUR MODERN DATA ECOSYSTEM
When 65 year old British sailor Jeanne Socrates sailed solo around the world in 2007, she didn’t just wake up, get in her sailboat, raise the sails, and go. She planned and she prepared, but circumnavigating the world wasn’t even her goal when she sailed a dinghy for the very first time in 1990. Having enjoyed it and building upon her foundation of knowledge, she practiced sailing on her dinghy for four years before taking up yachting in 1994. She didn’t complete her first long-distance cruise until 1997 when she bought her 38-foot yacht, Nereida, and sailed it home from Sweden. It would be another 10 years before she was ready to circumnavigate the globe for the first time.
Fortunately, as you embark on your journey to build a modern data ecosystem for your enterprise, it won’t take 17 years to reach a major milestone. In reality, and thanks to today’s technology, you can have your data ecosystem operating and producing insights and real tangible business value in a matter of months. But achieving such early wins can only happen if you have the right data strategy in place.
Once the idea of a long-distance cruise was in her mind, Socrates’ desire and ambition set the guidelines for the yacht she would need in order to reach her goals. Similarly, your ecosystem architecture will define and align the technical components needed to succeed in building your ecosystem, one that will support your current business needs and that scales to meet new demands year after year.
When Socrates set sail on her first nonstop circumnavigation, she had to know her route of safe passage and she had to have all of the resources she would need for each day of her trip before she left port. She also had to plan for contingencies in the event something went wrong. Similarly, understanding the needs of your organization, considering potential risks, and mapping out your data ecosystem before you start assembling the pieces will help you avoid catastrophic data storms.
Taking an agile approach to your modern data ecosystem using Data Vault, you’ll be able to build on your organization’s data ecosystem similar to how Socrates built upon her sailing knowledge. You too will discover great and unknowable aspirations once your Data Vault sets sail. Taking an agile approach will reduce friction as you scale and seek out new insight destinations.
Putting her boat on full autopilot, Socrates might have been able to visit all of the most interesting places in the coastal world while she slept. But unlike sailing the seas, there are simply too many destinations in data science and we must be arriving at all of them constantly – and at the same times. For your data ecosystem, automation is a necessity. Automating the flow of data accelerates the delivery of insights from Data Vault whether you’re at the helm of your data ecosystem or in your bed sound asleep.
Deployed to the cloud, your data ecosystem becomes infinitely more powerful while enabling you to control costs and prevent wasteful spend on unused technology resources. In the cloud, you could quite possibly run data operations from your bed at home.
On September 7, 2019, at 76 years of age, Socrates became the oldest person to ever solo circumnavigate the world non-stop. She did it while sailing Nereida, the same yacht she acquired from Sweden in 1997. It was a lofty achievement that she could not have comprehended even when she sailed her boat home for the first time. Combining a sound data strategy, a well-constructed data ecosystem, Data Vault, plus automation leads to rapid, incremental delivery of business value. Your modern data ecosystem will have a positive impact on your company, on your customers, and for your community – and in ways you can’t yet imagine.
What insights will you set sail in search of?
—-
ABOUT IMPACT MAKERS
We design, architect, engineer and implement modern advisory and data solutions to drive business and technical agility. We take a holistic approach to maximizing our impact – balancing our strategic expertise with technical depth, and our client-focused delivery with corporate purpose. Our unique social enterprise model attracts best-in-class consultants from the healthcare, financial services, and public sector industries we serve.
We are agents of change not only for our clients, but also for the communities we serve. Impact Makers is a benefit corporation and founding B-corp committed to contributing its profits and equity to the community. Since 2006, we have extended more than $3.2 million in direct gifts and pro-bono services to the nonprofit community.
If you’re interested in speaking to us about your data science or technology needs, book a complimentary exploratory session with a specialist and see how we can help you unlock tangible business value.