It’s great to see that a team at AWS has made COVID-19 datasets readily available to the public (read here for detailed information). The datasets are accessible from a public S3 bucket to anyone with an AWS account. For healthcare providers and payers that want to begin or enhance their analytical efforts around the coronavirus crisis, the COVID-19 data lake can be a useful accelerator.
What’s in the COVID-19 Data Lake?
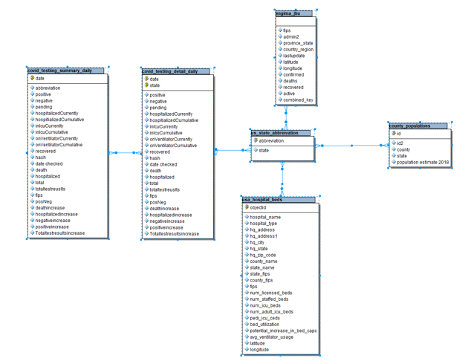
The datasets include COVID-19 cases (global and US) from Johns Hopkins University and The New York Times, hospital bed metrics from Definitive Healthcare, testing data from the COVID Tracking Project, and research articles from the Allen Institute for AI. AWS refreshes the data lake when sources provide updates.
Data Model of Selected Datasets
Developed with ER Studio
How can you mobilize the COVID-19 data?
There are several ways you can take advantage of this data.
First, you can query it in-place using AWS Athena, alone or joined with other public or private data. If you want to join it with other data already stored in S3, simply define Athena tables over the additional datasets. Keep in mind that all Athena query results will land in a single location for your Amazon account, so if you’re sharing the account with others and some of your data is sensitive, you’ll want to safeguard the query results.
If you have a preferred analytical data platform, such as a local SQL Server instance, a Parquet-based S3 data lake, or a Snowflake data warehouse, you can extract data from the COVID-19 lake, transform as you choose, and load to your platform.
Alternatively, you can skip the COVID-19 data lake and go straight to the AWS Data Exchange, where over two dozen COVID-19 datasets are available with free subscriptions.
What can you do with it?
- Combine case data with your patient visit data to get a better understanding of the penetration and location of infections
- Combine it with other data available on the AWS Data Exchange to:
- model effective resource deployment plans
- profile those affected by the virus, establishing treatment segments and future defenses
- model economic and company financial impacts
- identify vulnerable populations to help them apply for federal funding
- Build descriptive and predictive staffing and resource utilization models
- Inform your supply chain forecasts (find more about Impact Makers’ Supply Chain Forecasting here)
What would make it better?
One of the data gaps in the AWS COVID-19 data lake is daily testing data by county. Without this, analysts can’t draw a complete picture of test trends, cases, and hospital capacities at a granular level. We expect this gap is largely due to the inconsistent publishing of testing metrics by reporting agencies.
Additionally, varying grains across the datasets will require analysts to transform the data to make the data useful alongside corporate datasets.
Even so, the repository provides a great free resource for those looking to explore or make direct use of the information for company planning, response, or recovery throughout and beyond the COVID-19 pandemic.
Latest Posts
BE CURIOUS & APPROACHABLE
STANDS OUT FROM THE CROWD
MAXIMIZING MY IMPACT
GREAT WORK, GREATER CAUSE
[WEBINAR] Patagonia Unpacked – “All Profits to Charity” and the Social Enterprise Movement
[WEBINAR] Finding Corporate Success While Promoting Social & Environmental Responsibility (Video)
Visit Our Blog
Share This Post
Contact Us